Tags allow us to associate contextual key-value pairs with collected data.
After collection, tags can later be used as dimensions to break down the data and analyze it from various different perspectives to target specific cases in isolation even in highly complex systems.
Tags have keys and values. Examples of tags:
- {frontend: “web-0.12”}
- {frontend: “ios-10.2.12”}
- {http_endpoint: “server:8909/api/users”}
Frontend tag allow users to breakdown the data between web, iOS and Android users. HTTP endpoint allows to filter or group by a specific endpoint when looking at the HTTP latency data.
Propagation
Tags may be defined in one service and used in a view in a different service; they are propagated on the wire.
In distributed systems, a service is likely to be depending on many other services. This results in many challenges when analyzing the data collected at the lower ends of the stack. Instrumentation at lower layer might not be very valuable if data is not recorded with enough context.
Lower ends of the systems cannot have additional hardcoded context, this would leak details of higher levels services to the lower level. Instead, we use tag propagation. Higher level services produce tags, and lower-end uses them when recording data.
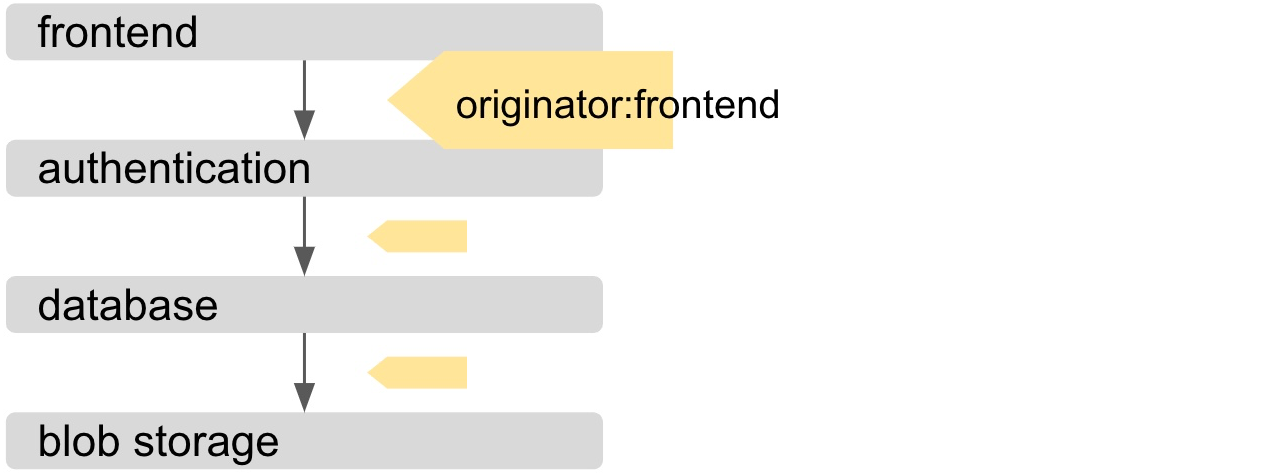
Above, frontend depends on the authentication service. Authentication service needs to query database that depends on the lower-level blob storage service. In this case the originator tag has been propagated as a part of the requests all through the stack. And blob storage can easily record data with the originator tag. The data analysis backends can group data by originator and blob storage service can tell the impact of higher level users on their service.